2022年の目標
2021年の反省を踏まえて、2022年の目標を立てる。
研究
博士号取得に向けた取り組み
定量的な目標は以下とする。
- ジャーナル投稿:1件以上
本当は2件にしたいけど、1件が妥当だと思う。 まずは投稿しよう!
国際会議投稿:1件以上
研究会投稿:2件以上
書けそうな結果が出たら、1ヶ月〜2ヶ月先の投稿先を決める。
- 特許出願:1件以上
定性的な取り組み
- 論文を読み、アウトプットすることを習慣づける 2021年の反省として、論文を読んだけど、まとめていないことが散見された。 そのため、読んだ論文は日々アウトプットしていくことにする。
日々のアウトプット
ブログ
2021年の振り返りでも書いたが、ちょこちょこ試行錯誤した結果を都度ブログ等に書いていくことにする。 自分は大したことないと思っていても、誰かの役には立つかもしれないから。 毎月1件以上のブログ記事は書くようにしつつ、日々の試行錯誤は都度出していきたい。
コミュニティへの参加
現在は、大学院と会社には所属しているが、それ以外のコミュニティについては特に参加をしていない。 2022年はコミュニティの方面へも積極的に参加していきたいと考えている。 ただ、どういったところへ参加していくかはまだ漠然としているので、色々考えていきたい。
OSSへの貢献
日頃お世話になっているOSSに対して、自身もコントリビュートできるような活動をしていきたい。 まずはリポジトリへのプルリクエストやissueを立てることによる貢献をイメージしている。 また、自身が研究や業務の中で作ったものを世の中へどんどん出して、他の人の貢献につながるような活動をしていきたい。
日々のインプット
読書
昨年の実績は22冊だった。インプット量の不足によりアウトプットができないことも感じていたので、今年は少し多めに設定しようと思う。また、例年、ガーッと読む月と全く読まない月があったので、ムラがないようにしたい。 幸いにも積読がなくなることはないだろうし、図書館も家の近くにあるので、時間を決めてどんどん読んでいこう。
今年の目標は月5冊で年間60冊を目標としたい。 これは数値面では、あまり理由はないが、昨年の2,3倍は読まないといけないとなんとなく感じたので、設定してみる。
他の人の書いた記事を読む
これまでfeedlyを使って記事を読んでいたけど、あまり使いこなしている感じはしない。 ここもきちんと定期的に読む仕組み作りからやろうと思う。 まずは、ざざーっと毎日読むような習慣作りをやろう。 そして、フィードも日々更新していかないといけないと思っている。
会社でも他の人のブログ記事が通知されるので、それは読んでいくようにしようと思う。自身の知らないことも多いので勉強になるし、良い刺激にもなると思う。
資格
TOEIC730点
2021年で取った自身の最高点数670点を超えるべく、730点を目標とする。直近では、1/30に試験を受けることにしているので、毎日コツコツと勉強するようにしよう。
統計検定 2級
統計検定2級を受験することにした。理由としては、確立・統計の知識に不足を感じているからである。やはり、統計的な問題解決力は持っていて損はないと思うので、資格を取る過程で体系的に学び直したいと思う。どうやら、1級以外はCBT方式での試験になったみたいなので、半年後の7月くらいを目安に学習を進めようと思う。
生活
新聞を読む
自分はけっこう新聞を読むことが好きなので、継続できているが、改めて宣言しておくことで習慣が途切れないようにしよう。
健康面
体重
年末年始で+2kg増えてしまった。。 例年、冬に増え、夏にかけて減っていく傾向にある。
まず、体重を毎日計測することにしよう。 記録して、自分の現状を日々見つめ直すことが重要である。 ついつい、食べすぎてしまった次の日などは計らないことが多いので、きちんと計ることにする。
毎日8,000歩、歩く
運動施策の推進|厚生労働省によると、毎日60分以上の散歩が基本とされている。60分散歩をすると、8,000歩くらいになると思うので、8,000歩を目標とする。
朝は幼稚園へ娘を送る際になるべく歩くことと、昼休みもなるべく歩くようにしよう。
運動習慣をつける
ジムを契約するか、何かスポーツでもやるか。 現実的には、公共の施設が安く利用できるので、そこを利用するつもり。 そして、予め予定を入れておくことにする(仕組み作り)。これは読書や他のことでも同じように心がける。
家族を大切に
家族と接するときは家族の事を第一にする。 他のことは考えない。空返事をしない(これは自身の悪い癖なので、意識して変えていこう)
投資
ふるさと納税
必ずやる。
株主優待の取得
自分はよくつなぎ売りで外食系の株主優待を取得している。今年も取得できるものは取得していく。
海外ETFをやる
つみたてNISAでインデックスファンドを毎月購入することや会社の制度で確定拠出年金があるので、利用している。 これらは定期的に毎月積み立てる仕組みを利用することで、無理なく継続できている。 海外ETFについても、年末に毎月1口ずつ、3銘柄購入することにしたので、毎月推移をみていこうと思う。
新しいことに挑戦
新しい場所に行くことや新しいことに挑戦することで、脳が活性化されて新しいアイデアや日々の生活に活気が出る。 いろんなことに興味関心を持ち、色んなところにアンテナをはっていこう。
2022年は、これまで以上に、自身がより成長でき、周りの人にも良い影響を与えられる年にしたい。 よろしくお願いいたします。
2021年の振り返り
大晦日の夜になってしまったけど、今年の振り返りを急いでしようと思う。
2021年の前半は、博士後期課程の研究を進めたり、転職をして本格的に研究を仕事とするようになったり、新しい環境に慣れるためのことをやっていたように思う。 後半は大学と会社での研究に挑みつつ、なかなか成果が出ずに悩んでいることが多かったように思う。
総じて言うと、まずは研究に専念できる環境作りを行うことができて良かったと思う。社会人博士として研究を進めるにはベストの環境に身を置くことができたと思っている。 一方で、対外的な成果は今一つ出せていないため、来年はより成果を意識し、内容を発展させられるよう取り組んでいく必要がある。 反省点としては、研究の作業を進めることを優先しすぎて、必要なインプットを疎かにしていたように思う。自分なりには、色々とやってきたけれども、成果に繋がっていない。もっと本を読んだり、ブログにちょこちょこ試行錯誤した小さな成果を積み重ねていくことからやっていこう。
転職
転職をした。 これまでの業務経験としてなかったWebエンジニア・研究員として一歩を踏み出すことができた。SlackやGithubのプルリクやissueの使い方などもほとんど知らなかったので、色々とキャッチアップしながら進めていった。(まだできていないところもあるだろう) ブランチを切らずにmasterへ直接pushをしたりもしたなぁ。 フルリモートワークの環境ではあるが、周りの方々のサポートもあり、日々進められていると思う。いつもありがとうございます。
国内発表
転職後4ヶ月で国内の研究会に発表することができた。
- 酒井 敏彦, 三宅 悠介, 栗林 健太郎, ハンドメイド作品を扱うECサイトに特化したBERTを用いた言語モデル構築に向けた取り組み, 情報処理学会 第250回自然言語処理研究会(NL), Vol.2021-NL-250, No.5, pp.1-5, 2021[link][発表資料]
研究
- 対外的なpublishはあまりできていないけれども、2021年当初と比べると、あともう少しのところまで来ている部分もある。 特に実験を進める上で発生するエラー等の対処やコードを動作させるスピードについては、2021年当初より格段に早くなっていると思う。 2022年は、より対外的な成果を意識していきたい。
資格
- TOEIC 670点(L:340, R:330)
大学で受けたTOEIC-IPテストは670で自己ベストを超えてたから良し。700まで早くいきたい
— tossy (@tshk_sakai) 2021年9月7日
9月に自身の最高点を取ることができた。しかし、3月末までに目標として730点を取得したいため、より英語力を高められるよう頑張ろうと思う。スタディサプリで意識して毎日1時間勉強できるようになった。(もちろんできない日もある)また、大学の研究室のつながりで毎週1回英語と日本語で話す機会があるので、英語学習のモチベーション維持できているのがありがたい。
2022年はTOEICだけでなく、自身の研究力の強化につながる資格も意識して取得していきたい。
読書
- 年間で22冊読了
月に3冊は読みたいので、目標を下回っている。毎日の中で読書する時間を確保するのが必要だと思う。予めこの時間は読書をするという優先的な時間の確保をすることが大事だと感じた。
本自体は図書館で借りたり、自身で購入する量は明らかに増加した。周りの方々からの影響も大きい。ブログやslack等の中でオススメ本の情報が得られるので、ありがたいと思う。
ブログ
新しく始めたこと
- 自身のポートフォリオのサイトを作った
- 9月ころから日記を書き始めた
奨学金完済
奨学金を完済した。借金がなくなるのは精神的に大きいなぁ。
奨学金完済した!
— tossy (@tshk_sakai) 2021年6月28日
家族と健康
子供の幼稚園の行事やイベントごとには積極的に行けている。みんな特に大きな病気もすることもなく、健康に過ごせたと思う。健康が一番なので、継続していきたい。
- 歩数
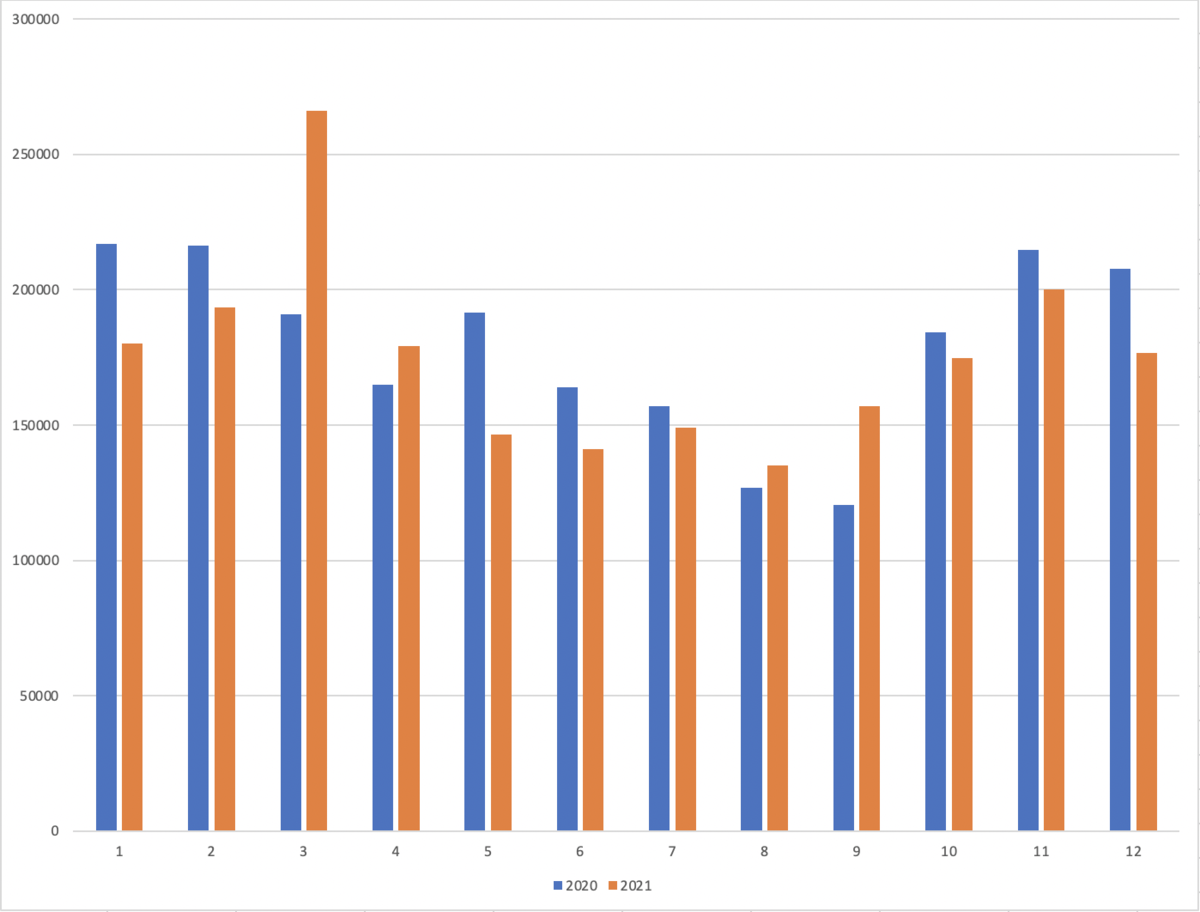 2020年よりも2021年は、全体で3%程度歩数が減少しているようだった。
やはり普段より、歩くことや運動習慣をつけないといけないと思う。
体重も10kgくらいは減らしたいと思っているので、適度な食事制限と運動量を増やすことを心がけたい。
2020年よりも2021年は、全体で3%程度歩数が減少しているようだった。
やはり普段より、歩くことや運動習慣をつけないといけないと思う。
体重も10kgくらいは減らしたいと思っているので、適度な食事制限と運動量を増やすことを心がけたい。
2022年に向けての抱負
2022年は整った環境の中で成果を出していけるよう新たに仕組み作りをして行く必要があると思う。 また、改めて来年目標設定をしよう。
読書、勉強、研究などの時間を予め確保し、取り組む
発表する場を予め設定、1週間・1ヶ月・半年・1年スパンの目標設定を行う
体力作り(ジムや日常で運動量を増やす)
Huggingfaceのtransformersライブラリで固有表現抽出
Huggingfaceのtransformersライブラリでv3.4.0を使う
固有表現抽出をtransformersライブラリで行う。 東北大学のBERTモデルを使う場合は、Huggingfaceのtransformersライブラリでv3.4.0を使う必要がある。
- 東北大モデル以外(NICT, 京大など)なら、最新のtransformersが使える(examples/pytorch/token-classification/run_ner.py)。入力ファイルはjsonにするのがおそらく楽で、jsonファイルは1行に1文の情報で、単語列とラベル列からなるもの。
— Tomohide Shibata (@stomohide) 2021年9月14日
何か見落としなどあれば教えてください。
上記のツイート通り、BertJapaneseTokenizerがfastに対応していないので、最新のtransformersのrun_ner.pyでは使えない https://github.com/huggingface/transformers/issues/12381
transformersのtokenizerはv4.0.0以降でFastTokenizerがデフォルトで使用されるようになった
これまでtransformersのtokenizerはライブラリ内に同梱される、python実装のものであった。 一方、v4.0.0以降でFastTokenizerという名称でとして使用されるようになった。また、このトークナイザはtokenizersとして分離された。
動かす
cloneしてくる
git clone git@github.com:huggingface/transformers.git -b v3.4.0 cd examples/token-classification
データの準備と環境変数の設定
curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \ | grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \ | grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \ | grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp export MAX_LENGTH=128 export BERT_MODEL=bert-base-multilingual-cased python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt export OUTPUT_DIR=germeval-model export BATCH_SIZE=32 export NUM_EPOCHS=3 export SAVE_STEPS=750 export SEED=1
実行
python3 run_ner.py --data_dir ./ --labels ./labels.txt --model_name_or_path $BERT_MODEL --output_dir $OUTPUT_DIR --max_seq_length $MAX_LENGTH --num_train_epochs $NUM_EPOCHS --per_device_train_batch_size $BATCH_SIZE --save_steps $SAVE_STEPS --seed $SEED --do_train --do_eval --do_predict
train.txtなど一番初めに実行されたファイルを元にcachedファイルが作成される
上記を実行したあと、途中でtrain.txt,test.txtを変更しても反映されてないっぽかった。 結論としては、一番初めに実行した際のtrain.txtが反映されているようだ。
TokenClassificationDatasetクラス https://github.com/huggingface/transformers/blob/eb0e0ce2adf66d2b1106b9e0852f6e063ab9ae7c/examples/token-classification/run_ner.py#L179
以下の部分でcachedを作る、このcachedファイルを削除し、run_ner.pyを動かすと、以下のエラーで止まる。 https://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/examples/legacy/token-classification/utils_ner.py#L236
Traceback (most recent call last):
File "run_ner.py", line 317, in <module>
main()
File "run_ner.py", line 183, in main
TokenClassificationDataset(
File "/Users/xxxxx/Documents/GitHub/transformers-v3.4.0/examples/token-classification/utils_ner.py", line 247, in __init__
examples = token_classification_task.read_examples_from_file(data_dir, mode)
File "/Users/xxxxx/Documents/GitHub/transformers-v3.4.0/examples/token-classification/tasks.py", line 24, in read_examples_from_file
with open(file_path, encoding="utf-8") as f:
FileNotFoundError: No such file or directory: './train.txt'
cachedファイルの削除を行い、もう一度、train.txtを少なく作 り直すと、作り直したtrain.txt等で動作した。
run_ner.pyのis_world_masterをis_world_process_zeroに変更しておく
他に、以下のエラーが出たが、モデルはOUTPUT_DIRで指定したgermeval-modelへ保存された。
Traceback (most recent call last):
File "run_ner.py", line 317, in <module>
main()
File "run_ner.py", line 258, in main
if trainer.is_world_master():
AttributeError: 'Trainer' object has no attribute 'is_world_master'
このエラーについてはis_world_masterをis_world_process_zeroに変更することでエラーが解消した
BERTで固有表現抽出を行う際の特殊トークン'X'について
BERTで固有表現抽出を行う際に、BERTでの特殊トークン'X'を学習時に使う場合があった。
固有表現抽出を行う際に特殊トークン'X'を学習に利用していた
固有表現抽出では、単語ごとにラベリングをして、ラベルに基づきモデルが学習を行う。 BERTへ文章を入力する時に、一般的にサブワード化が行われるが、このサブワード化により、単語がトークンの単位になると、単語ごとに付与したラベルがずれてしまうケースが発生する。 上記の理由から、About 'X' label#1のissueやBERTのv1の論文にも記載されている通り、最初は学習時に'X'は必要という話だった。 例えば、以下のようにラベル付けをしたとする。
Jim Henson was a puppeteer B-PER I-PER O O O
上記の文をサブワード化すると、ラベリングした単語が分割されてしまう。
以下の例では、サブワード化した際の##のトークンには、元のラベルをそのまま使用している。
Jim Hen ##son was a puppet ##eer B-PER I-PER I-PER O O O O
この場合、当初には意図していない「##son」と「I-PER」というラベルや「##eer」と「O」というラベルが学習に使われてしまう。
そこで、単語の最初のトークンにはオリジナルのラベルを残し、その単語のサブワードされた##のトークンには'X'というラベルを使うことがBERTの原著論文v1の中でも挙げられている。 具体的には、4.3 NERの章に記載されている。
sub-token as input to the classifier. For example: Jim Hen ##son was a puppet ##eer I-PER I-PER X O O O X Where no prediction is made for X. Since the WordPiece tokenization boundaries are a known part of the input, this is done for both training and test. A visual representation is also given in Figure 3 (d). A cased WordPiece model is used for NER, whereas an uncased model is used for all other tasks.
これを読むと、WordPieceによりtokenizeされた先頭以外、'X'は予測しないということが書かれている。
現在は特殊トークン'X'は利用されていない
一方、現在最新であるBERTの原著論文v2にはこの記載は消えているように思える。
v2のBERT論文を見ると、'X'を使わずに、「文書情報を使う」ことで'X'を使う場合と同等の性能を得た、と書かれている。
BERTの原著論文v2には以下のような記載がある。
5.3 Feature-based Approach with BERT We use the representation of the first sub-token as the input to the token-level classifier over the NER label set.
5.3章の中段あたりに、サブワードの最初のトークンにラベルをセットする、と書かれている。'X'との記載もないため、現在は'X'を使っていない。
また、さきほどのissueにも、'X'を使わずにサブワードの最初の単語のみをfine-tuningで学習することでモデルがパターンを学習できるとしている。
For example After extracting features for the sentence below Jim Hen ##son was a puppet ##eer You're giving only [Jim , Hen , was , a, puppet] hidden states to linear classification layer ?
Yes. Because I think the fine tune bert could learn this pattern.
参考:https://github.com/kamalkraj/BERT-NER/issues/1#issuecomment-474266192
また、以下の記事にも'X'の言及がされている。
BERT uses WordPiece tokenization rather than whole-word tokenization (although there are whole words in its vocabulary). So if you have a word like “personally,” it may be broken up into “person” “##al” “##ly.” You now have a list of WordPieces which is much longer than, and misaligned with, your list of labels. You as the practitioner need to figure out how to handle cases where you have one tag per word, but some words get broken up into several chunks. I wrote a function called tokenize_and_preserve_labels to propagate a word’s original label to all of its pieces during tokenization. Other folks who implemented this have also used the following heuristic: leave the original label on the first token of the word, then use the label “X” for subwords of that word. Either method seems to result in equally good model performance.
まとめ
BERTで固有表現抽出を行う際の特殊トークン'X'は、モデルのfine-tuning時に過去使われていた。 現在は使われていないようだ。
「【新版】日本語の作文技術」を読んだ
「【新版】日本語の作文技術」を読んだので、今後自分の中で文章を書く際に、ポイントを引き出せるようにまとめておく。
本書の裏表紙には、こう書かれている。
「目的はただひとつ、読む側にとってわかりやすい文章をかくこと、これだけである」。修飾の順序、句読点のうちかた、助詞の使い方など、ちゃんとした日本語を書くためには技術がいる。
これまで、いろんな文章を書いてきたけれど、修飾の順序や句読点のうちかた、助詞をどう使うかなどはあまり気にしてこなかったように思える。 この本を読んで学んだことをこれから実践し、読む側にとってわかりやすい文章にしていきたいと思う。
以降は、本書を読んだ際のポイントを自分なりにまとめたものである。
修飾する側とされる側
ポイント:修飾する側、される側が離れすぎている場合、わかりにくい文章となる。
文章がわかりにくい場合には、修飾する側と修飾される側を化学構造的に書き表してみる。どの単語がどの単語を修飾しているのか、という関係性を見ていくとわかりやすい文章となる。
修飾の順序
修飾語の語順には4つの原則がある。
特に、1.と2.が重要である。
- 節を先に、句をあとに
- 長い修飾語ほど先に、短いほどあとに
- 大状況・重要内容ほど先に
- 親和度(なじみ)の強弱による配置転換
の理由としては、句が節よりも先にきてしまうと、句が節の中の先の方の名詞を修飾してしまうからである。 例えば、紙を形容する修飾語が「白い」、「横線の引かれた」、「厚手の」という3種類だった場合を考える。 この場合、句が節より先に来る場合、「白い厚手の横線の引かれた紙」となる。これは、「白い厚手」が「横線」を修飾することになってしまう。一方、節が句より先に来る場合は「横線の引かれた厚手の白い紙」となり、わかりやすい。
は、単純に短い修飾語をあとにしたほうがわかりやすい文章になるという原則である。 例えば、本書の中で書かれている以下の文章では、(A)のほうがわかりやすい。これは短い修飾語である「私は」があとにきているからである。
(A). 「明日はたぶん大雨になるのではないかと私は思った。」
(B). 「私は明日はたぶん大雨になるのではないかと思った。」
句読点の打ち方
第一原則 長い修飾語が二つ以上あるとき、その境界にテンをうつ。
第二原則 原則的語順が逆順の場合にテンをうつ。
また、この原則以外に思想の最小単位を示す自由なテンがある、と本書にはある。 第二原則における原則的語順が逆順とは、修飾の順序の「節を先に、句をあとに」や「長い修飾語ほど先に、短いほどあとに」の原則が使われていない場合である。この場合、テンが必要になってくる。
漢字とカナの使い分け
漢字とカナは併用すると視覚としての言葉のまとまりが絵画化されるので、わかりやすくなる。 そのため、どういうときに漢字を使い、どういうときに使うべきではないか、は上記のイメージを持てば使い分けできる。 例えば、以下の文章を考える。
- その結果今腸内発酵が盛んになった
- その結果いま腸内発酵が盛んになった
前後で漢字が続けば、「いま」と書く方がわかりやすいし、ひらがなが続けば、「今」と書くほうがよい。そのため、この文章であれば、後者の文がわかりやすい。
助詞
係助詞「ハ」
係助詞「ハ」 には題目を表す使い方と対照(限定)を表す使い方がある。
題目を表す使い方であれば、「象は鼻が長い」
対照(限定)を表す使い方であれば、「蛙は腹にはヘソがない」
「まで」と「までに」
- 来週までに掃除せよ
- 来週まで掃除せよ
「までに」という表現であれば、来週までに一度掃除すればよいということがわかるが、 例えば、「来週まで掃除せよ」であれば、来週まで一週間掃除しつづけるようにもとれる。
接続助詞の「ガ」
「〜が」の用法には、反対や因果関係もなく、「そして」というような二つの句を繋ぐ使い方がある。これは読む側が逆説かな、と思ったりすることもあるため、読みにくくなる。
並列の助詞
サルとイヌとネコとがけんかした
例えば、「サルとイヌとネコがけんかした」という文章だと、サルとイヌのペアがネコとけんかしたともとれる。これを防ぐために、「とが」をつけることで三者が入り乱れてけんかしたことを表現できる。
また、日本語は後置詞的言語であるため、以下のように記載する方が良い。
- ○ 出席したのは山田と中村・鈴木・高橋の四人だった。
- × 出席したのは山田・中村・鈴木と高橋の四人だった。
段落
段落はかなりのまとまった思想表現の単位である。 段落ごとに何を言いたいのか、何を述べたいのか、を意識して書くことが重要である。
段落のいいかげんな人は、書こうとしている思想もまたいいかげんで、不正確で、非論理的だとみられても仕方がないであろう。
まとめ
最後に、本書で読んだことを意識して文章を書いていきたいと思う。
深層学習を使った固有表現認識のサーベイ論文
IEEE Transactions on Knowledge and Data Engineering 2020の論文。
深層学習を使った固有表現認識のサーベイ論文。 ieeexplore.ieee.org
5章 今後の方向性
5.1 チャレンジ
データのアノテーションの課題
データのアノテーションには時間とコストがかかる。リソースの乏しい言語や特定のドメインによってはアノテーションを行うのに専門家が必要となるため、大きな課題となっている。
また、言語の曖昧さのためアノテーションの品質と一貫性の課題がある。 同じ単語でも違うラベル付けがされていることがある。 例えば、以下の文で考える。
Baltimore de feated the Yankees
上記の文章中の「Baltimore」は、MUC-7ではLocation、CoNLL03ではOrganizationとラベル付けされている。
他にもEmpire StateとEmpire State Buildingは、エンティティの境界が曖昧なためCoNLL03とACEのデータセットでは同じLocationとラベル付けされている。
informalなテキストへの対応
ニュース記事のような正式な文書ではまずまずの結果が報告されているが、ユーザが生成するテキストではF値は40%程度となっている。
informalなテキスト(ツイート、 コメント、ユーザフォーラムなど)の固有表現認識は文が短いこととノイズが多いことから現状は難しいと考えられている。
現時点(2021/6/26)だとF値60.45がSOTAとなっている。
5.2 将来の方向性
NERの細粒度と境界検出
細粒度NERではラベル数の大幅な増加により複数のラベルタイプをつける必要があり、複雑さの課題がある。 このことからB-I-E-SとOをdecodeタグとして使用することでエンティティの境界とラベルを同時に検出するようなNERのアプローチを考える必要がある。
NERとEntity linking(EL)の統合
既存研究ではNERとEntity linking(EL)は別々のタスクとして扱われている。 NERとEL、エンティティの境界検出、エンティティのリンク、エンティティタイプの分類をうまく組み合わせることで各タスクが他のタスクの部分的な出力から恩恵を受けることができ、エラーの伝播を軽減できるのではないか。
informalなテキストにおけるDeep learningベースのNER
informalなテキストでのNERのパフォーマンスはまだまだ低い結果となっている。 ユーザが生成するテキストの辞書を補助リソースとして活用していくことがパフォーマンスを上げることにつながる。 辞書をどのように取得するか、どのように組み込んでいくかが課題となる。
スケーラビリティ
データのサイズが大きくなった時のパラメータの指数関数的な増加を最適化するための仕組みが必要である。 例えば、ELMoは各単語を3 × 1024次元のベクトルで表現し、32GPUで5週間の学習、Google BERTは64個のCrowd TPUで学習が必要である。 エンドユーザがこういった強力なコンピューティングリソースにアクセスするのは難しい。 今後モデルの学習に必要な計算時間を削減するためにモデルの圧縮や枝刈り等の技術も必要になる。
転移学習
あるデータセットで学習したモデルは言語の特性やアノテーションの違い等により他のテキストへ転用した際にうまく動作しないことがある。NERに深層学習の転移学習を行う研究はいくつかあるが、まだ十分に検討されていない。
今後は以下のような研究課題に取り組む必要があると考える。
- あるドメイン領域から異なるドメイン領域への効率的に知識を転移すること
- NERタスクでのzero-shot学習, one-shot学習, few-shot学習の研究
- クロスドメインでのドメインミスマッチとラベルミスマッチへの対処
ツールの整備
データ処理、入力表現、context encoder、tag decoder、有効性の測定などを備えたツールは開発者をサポートすることができると考える。このようなツールができれば専門家に限らず一般の人にも有益であると考える。
タグの階層を使って異なるタグセットを活用する固有表現認識
ACL 2019の論文。
概要
異なるデータセットに出現するタグセットからタグの階層を人手で定義して、その階層構造をNERに利用する。
ベースラインモデルはneural NER(Lample et al.2016)
ベースライン1(M_Concat):全ての学習データの連結→粒度が異なるタグも一緒になってしまう問題がある(例) City vs. Address
ベースライン2(M_Indep):セパレートモデル→各タグで学習し、2つのモデルを作成。最終的な2つのモデルの出力を統合する必要がある。
ベースライン3(M_MTL):マルチタスキング→テキスト表現を共有し、タスク毎に適用できる。こちらも最終的なモデルの結果を統合する必要がある。
提案手法
M_Hier:タグの階層性を用いることで上記のベースラインのモデルの課題を解決する。
 提案手法では一番粒度の小さいFine-grainedタグのみを推測する。出力をタグセットに応じて変換する。例えば、Streetを推測した場合はタグセットに応じてLocationへ変換する
提案手法では一番粒度の小さいFine-grainedタグのみを推測する。出力をタグセットに応じて変換する。例えば、Streetを推測した場合はタグセットに応じてLocationへ変換する
結果
医療用データセットI2B2'06とI2B2'14で学習。
 F1-scoreで評価。結果としてM_Hierがどちらのデータセットでも良い結果となった。また、Physioでは一番良い精度となった。
ベースラインはいずれもコリジョンが起きたため、精度が落ちたと考えられる。
F1-scoreで評価。結果としてM_Hierがどちらのデータセットでも良い結果となった。また、Physioでは一番良い精度となった。
ベースラインはいずれもコリジョンが起きたため、精度が落ちたと考えられる。